
A method of machine learning has proven capable of turning 2D images into 3D models. Created by researchers at multi-million-dollar GPU manufacturer NVIDIA, the framework shows that it is possible to infer shape, texture, and light from a single image, in a similar way to the workings of the human eye.
“Close your left eye as you look at this screen. Now close your right eye and open your left,” writes NVIDIA PR specialist Lauren Finkle on the company blog, “you’ll notice that your field of vision shifts depending on which eye you’re using. That’s because while we see in two dimensions, the images captured by your retinas are combined to provide depth and produce a sense of three-dimensionality.”
Termed a differentiable interpolation-based renderer, or DIB-R, the NVIDIA rendering framework has the potential to aid, and accelerate various areas of 3D design and robotics, rendering 3D models in a matter of seconds.
Making 3D from 2D
As explained by Finkle, the 3D world we live in is actually seen through a 2D lens – otherwise deemed stereoscopic vision. Depth is created in the brain by combining images seen through each eye, creating the sense of a 3D image.
Based on a similar principle, DIB-R is capable of transforming input from a 2D image into a map, predicting shape, color, texture and lighting of an image. This map is then used to shape a polygon sphere, creating a 3D model representing the object in the original 2D image.
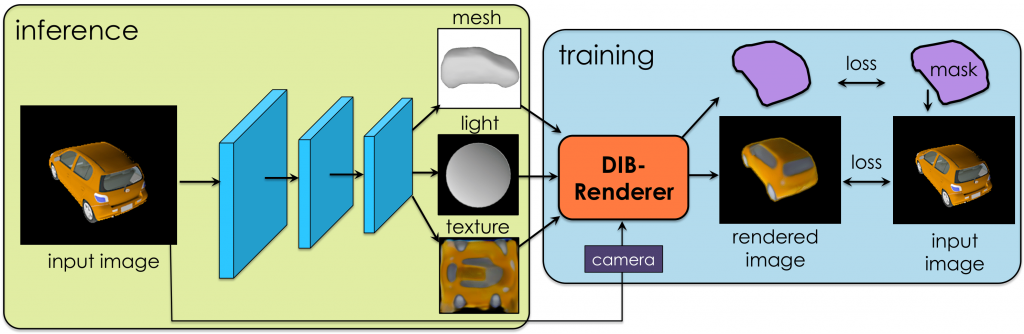
To achieve high 3D modeling speeds, DIB-R must be trained first with a wide dataset of images. One of the tests the team has performed so far is with a series of bird photos. All of the photos are RGBA modeled. After two days of training the framework using a single NVIDIA V100 GPU, it could produce a 3D object from a 2D image in less than 100 milliseconds. The results can be seen below.

Giving sight to autonomous robots
One of the potential applications of such a framework is in the development of autonomous robots, capable of understanding the environment around them and perceiving depth. Another application is in the creation of rapid 3D mockups based on 2D sketches, i.e. for architecture and product design.
For Jonathan Beck, founder of 3D art heritage project Scan the World, the process also has certain implications in photogrammetry – a method commonly used for the rendering of real-world 3D objects into digital, 3D models. “I’ve seen something similar before made by independent developers but this is the first time it’s been released by a big organization,” Beck states. “It would be interesting to see how this leads into photogrammetry, where an AI can assume parts of a missing sculpture from other images. Much like how the Artec 3D scanner can calculate the form of an object if there are gaps in the scan data.
“AI can help create a bridge where 3D scanning cannot currently deliver.”
More details of the NVIDIA project can be found in this dedicated microsite, and in the paper “Learning to Predict 3D Objects with an Interpolation-based Differentiable Renderer.” The research is conducted and authored by Wenzheng Chen, Jun Gao, Huan Ling, Edward J. Smith, Jaakko Lehtinen, Alec Jacobson, and Sanja Fidler.
Subscribe to the free 3D Printing Industry newsletter for the latest research developments. You can also stay connected by following us on Twitter and liking us on Facebook.
Looking for a career in additive manufacturing? Visit 3D Printing Jobs for a selection of roles in the industry.
Featured image shows 3D models of cars created from 2D source images. Image via NVIDIA
